人工知能(AI)の学習用データの確保と活用に対する需要が増えている中、放送映像コンテンツがAI学習用データとして構築される。
科学技術情報通信部(長官:ユ・サンイム、以下「科学技術情報通信部」)と韓国電波振興協会(会長:ホン・ボムシク)は、放送・メディア(メディア)のAI転換を加速し、韓国型AIモデル開発を支援するため、6月5日から7月4日まで「放送映像AI学習用データ構築事業」を公募すると発表した。
今回の事業には総額200億ウォンが投入される。科学技術情報通信部は、放送局、AI技術企業、データ加工企業、研究機関がともに参加する4つのコンソーシアムを選定し、それぞれに48億3000万ウォンを支援する予定だ。
選定されたコンソーシアムは、放送局が保有する映像を1万時間以上確保しなければならない。そして、確保された映像の中で著作権や個人情報上の問題がない場面を選び、計5000時間以上のAI学習データを構築する。このデータには、人物の話し方、表情、背景など、さまざまな情報が含まれる。AIが学習できるように、精製と加工の過程を経る。

放送映像AI学習用データの構築・活用手順も設置される(資料提供=科学技術情報通信部)。
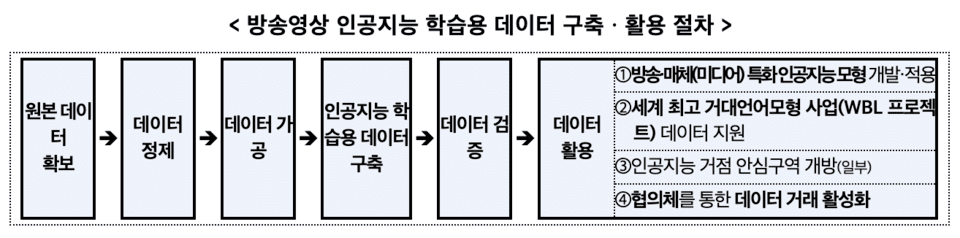
科学技術情報通信部は、データの品質を保証するために専門機関を通じて段階的な検証を実施する。データ構築の過程全般を点検し、AIモデルでテストも行う。コンソーシアムは、構築したデータを活用し、放送コンテンツの制作・サービスに適用可能なAI技術も共に開発する必要がある。
科学技術情報通信部は、構築されたデータを「世界最高の巨大言語モデル(World Best LLM)」開発事業に提供する計画だ。AI関連研究や教育にも使用できるように、一部データは開放される。
放送映像を基盤としたAIデータ取引も拡大する。これまで取引体系の不備などで放送映像AIデータ取引が活性化しなかったが、今回の協議体を通じて放送映像AI学習用データの現況を公開し、データ取引基準などを設け、データ取引を促進する計画だ。
科学技術情報通信部のカン・ドソン放送振興政策官は、「国内の放送局が70年間蓄積してきた放送映像は、言語と行動を豊かに含んでおり、韓国型AIモデルを学習させるための最適なデータと評価されている」とし、「国内放送映像コンテンツがAI発展の核心要素であるデータとして活用されるよう積極的に支援する」と述べた。